Show the code
# Import libraries
import pandas as pd
import numpy as np
import zipfile
import os
import requests
from pathlib import Path
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inlineThis is the technical version of an article that analyzes flight information from January 2022 to February 2023 (the latest available as of today). Of great interest are flight delays.
# Import libraries
import pandas as pd
import numpy as np
import zipfile
import os
import requests
from pathlib import Path
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inlineThe best resource to investigate the regularity of flights within the US is the Bureau of Transportation Statistics. They have a website that hosts the data, which is publicly available. The data is available by month, meaning that I had to manually request data for the 14 months I was interested in.
We can automate this download with the requests library of Python, setting START_YEAR to the beginning year of the period of interest and END_YEAR to the end year (exclusive).
START_YEAR = 2022
END_YEAR = 2024os.mkdir("data")for i in range(START_YEAR, END_YEAR):
for j in range(1,13):
# We set verify to False because an SSL cert error gets thrown otherwise for some reason.
# For some reason, creating a pool manager as described on the Certifi documentation
# throws an SSL connection error. It could be an issue with Google Colab, which I am using to
# work with this notebook.
r = requests.get(f"https://transtats.bts.gov/PREZIP/On_Time_Reporting_Carrier_On_Time_Performance_1987_present_{i}_{j}.zip", verify=False)
with open(f"data/On_Time_Reporting_Carrier_On_Time_Performance_1987_present_{i}_{j}.zip", "wb") as fd:
fd.write(r.content)At this point, we have a bunch of zip files, one for each month of flights. We’ll unzip them one-by-one.
#Construct an array to hold our zip filepaths
zips = []
for root, directories, filenames in os.walk('data'):
for directory in directories:
dpath = os.path.join(root, directory)
for filename in filenames:
fpath = os.path.join(root,filename)
if fpath[-3:] == 'zip':
zips.append(fpath)
for zip_path in zips:
try:
my_zip = zipfile.ZipFile(zip_path, 'r')
my_zip.extractall('data')
except zipfile.BadZipFile:
continueNow, we read the data in and clean it. We start out by reading in an arbitrary month to get a DataFrame with the correct columns, then loop through each month’s flight records (stored in a csv). We add each month’s flight records to our flights DataFrame; at this point, we are done loading data for this project.
Cleaning the DataFrames involves several steps. To start, we read in this HTML table from the Bureau of Transportation Statistics as a DataFrame. This table matches airlines with abbreviations. To aid legibility, we replace the abbreviations contained in our flights DataFrame with the airlines’ full names.
import re
#Obtains DataFrame with correct columns
flights = pd.DataFrame(columns=pd.read_csv("data/On_Time_Reporting_Carrier_On_Time_Performance_(1987_present)_2022_5.csv").columns)
#Concatenates inputs to flights DataFrame
for root, directories, filenames in os.walk('data'):
for filename in filenames:
fpath = os.path.join(root,filename)
if (fpath[-3:] == 'csv') & (fpath[5:8] == 'On_'):
a = pd.read_csv(fpath)
# Filter out unneeded rows (only keep things relevant to flight origin, airline, and departure delay)
a = a.filter(['CRSDepTime', 'DepDelayMinutes', 'Reporting_Airline', 'TaxiOut', 'Origin', 'Flight_Number_Reporting_Airline'], axis=1)
# Concatenate month table to flights
print(f" {fpath}")
flights = pd.concat([flights, a], ignore_index=True, join='inner')
# Obtains a DataFrame version of the HTML table on the BTS Airline Codes webpage
codes = pd.read_html("https://www.bts.gov/topics/airlines-and-airports/airline-codes")[0]
flights = flights.merge(right=codes, left_on='Reporting_Airline', right_on='Code', suffixes=['',''])#.drop(["Reporting_Airline", 'Code'], axis=1)We now make a copy of flights called delays. We can now safely transform our data and keep the original flights available for later analysis. We’ll also regularize our time (converting the HHMM format to HH.MM, where MM is out of 100 instead of 60).
# Makes a deep copy of flights called delays for transformation in this section. Filter out on-time flights.
flights['CRSDepTime'] = flights['CRSDepTime'] % 100 * 5/3 * .01 + flights['CRSDepTime'] // 100
flights['delay'] = flights['DepDelayMinutes'] > 0
delays = flights.copy(deep=True)[flights['DepDelayMinutes'] > 0]Let’s take a precursory view of flight delays in the aggregate and see how they correlate with departure time.
sns.set_theme()
f, ax = plt.subplots(figsize=(7, 7), sharex=True, sharey=True)
a = sns.histplot(data=delays, x='CRSDepTime', y='DepDelayMinutes', bins=[12,600],
cmap=sns.color_palette("flare_r", as_cmap=True), cbar=True, cbar_kws={'label': 'Quantity of delays'})
sns.kdeplot(data=delays.sample(1000), x='CRSDepTime', y='DepDelayMinutes', levels=5, color="w")
plt.title('Density of delays by departure time, ' + str(START_YEAR) + "-" + str(END_YEAR - 1))
plt.xlabel('Departure time')
plt.ylabel('Departure delay, in minutes')
plt.xlim((0, 24))
plt.ylim(bottom=0, top=90)
plt.xticks(range(0,24,4), ['12am','4am','8am','12pm','4pm','8pm'])([<matplotlib.axis.XTick at 0x7fa796f36290>,
<matplotlib.axis.XTick at 0x7fa796f35c00>,
<matplotlib.axis.XTick at 0x7fa7d57ca740>,
<matplotlib.axis.XTick at 0x7fa7894ad390>,
<matplotlib.axis.XTick at 0x7fa7894ac340>,
<matplotlib.axis.XTick at 0x7fa7894ae500>],
[Text(0, 0, '12am'),
Text(4, 0, '4am'),
Text(8, 0, '8am'),
Text(12, 0, '12pm'),
Text(16, 0, '4pm'),
Text(20, 0, '8pm')])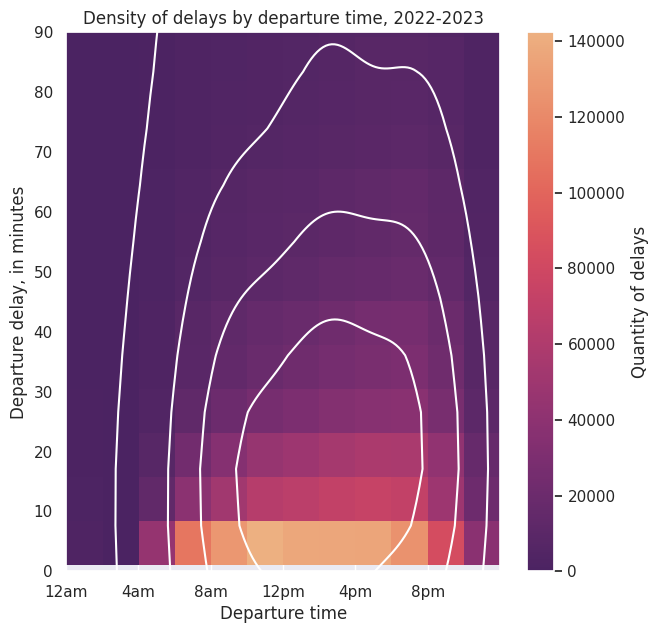
We see that delays overall are densest between 2pm and 6pm, but the most common delay is less than 10 minutes and occurs between 10am and 12pm. Given that the most common delay is minimal, I wanted to take a better look. We’ll look at significant delays, which I will define to be greater than or equal to 30 minutes in length.
def delay_significance(x):
"""Categorizes delays into one of three categories."""
if x == 0:
return "On Time"
elif x < 30 and x > 0:
return "Slight Delay"
else:
return "Significant Delay"
#Creates labels for hue sorting on histogram.
flights['Delay Status'] = flights['DepDelayMinutes'].apply(delay_significance)sns.histplot(flights, x='CRSDepTime', kde=True, hue='Delay Status',
binwidth=1, kde_kws={'bw_adjust': 3}).set(xlabel='Departure time', title='Flights from '
+ str(START_YEAR) + ' to ' + str(END_YEAR - 1) + ', by hour')
plt.xlim(0,24)
plt.xticks(range(0,24,4), ['12am','4am','8am','12pm','4pm','8pm'])([<matplotlib.axis.XTick at 0x7fa7849715d0>,
<matplotlib.axis.XTick at 0x7fa7849715a0>,
<matplotlib.axis.XTick at 0x7fa784972a40>,
<matplotlib.axis.XTick at 0x7fa7858f0b80>,
<matplotlib.axis.XTick at 0x7fa7858f1630>,
<matplotlib.axis.XTick at 0x7fa7858f20e0>],
[Text(0, 0, '12am'),
Text(4, 0, '4am'),
Text(8, 0, '8am'),
Text(12, 0, '12pm'),
Text(16, 0, '4pm'),
Text(20, 0, '8pm')])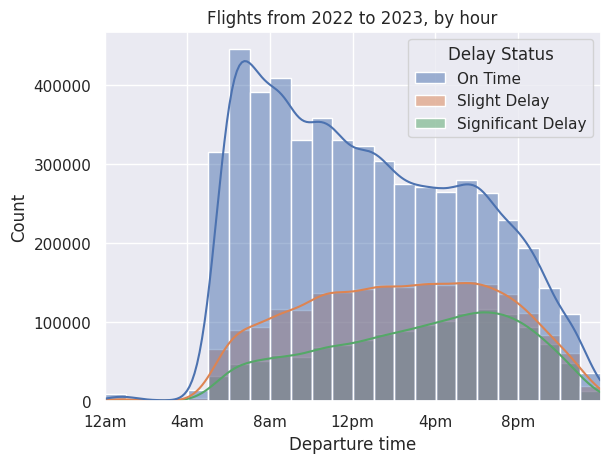
From the chart, we see that both slight and significant delays increase as the day goes on. Significant delays start low at 6am and steadily increase, peaking at 6pm, while slight delays seem to plateau around 10am.
Now, let’s look at delays by airline. We merge wholly-owned subsidiaries with their parent company (a complete list of wholly-owned subsidiary airlines in North America can be found on Wikipedia), as people do not often see their brand nor purchase from them. Some airlines, such as Republic Airline, are regional airlines that fly under multiple airline names; our data does not represent whose banner they fly under for a given flight, making it impossible for us to merge their flights with their contracted carrier.
# Adds new departure hour columns to flights and delays for easier charting
flights['CRSDepHour'], delays['CRSDepHour'] = flights['CRSDepTime'] // 1, delays['CRSDepTime'] // 1
#Selects only for significant delays
delays = delays[delays['DepDelayMinutes'] >= 30]
# Merges wholly-owned subsidiary airlines with their parent companies
delays_ma = delays.replace(to_replace={"Airline": {"Horizon Air":"Alaska Airlines Inc.", "Envoy Air":"American Airlines Inc.", "PSA Airlines Inc.":"American Airlines Inc.", "Endeavor Air Inc.": "Delta Air Lines Inc."}})
flights_ma = flights.replace(to_replace={"Airline": {"Horizon Air":"Alaska Airlines Inc.", "Envoy Air":"American Airlines Inc.", "PSA Airlines Inc.":"American Airlines Inc.", "Endeavor Air Inc.": "Delta Air Lines Inc."}})
def airline_delay_frequencies(airline, delays, flights):
"""Returns delay proportions, grouped by departure hour and departure time."""
total_delays = delays[delays['Airline'] == airline].groupby('CRSDepHour')['CRSDepTime'].count()
total_flights = flights[flights['Airline'] == airline].groupby('CRSDepHour')['CRSDepTime'].count()
return (total_delays / total_flights).reindex(np.arange(24), fill_value=0) * 100
# Accumulates multiple airline Series into a DataFrame for line plot
airlines = ['American Airlines Inc.', #'SkyWest Airlines Inc.',
'Alaska Airlines Inc.', 'United Air Lines Inc.',
'Delta Air Lines Inc.', 'Frontier Airlines Inc.', #'Allegiant Air',
#'Hawaiian Airlines Inc.',
'Spirit Air Lines',
'Southwest Airlines Co.', #'Mesa Airlines Inc.', 'Republic Airline',
'JetBlue Airways']
proportions = pd.DataFrame()
for airline in airlines:
proportions[airline] = airline_delay_frequencies(airline, delays_ma, flights_ma)# Constructs a bar plot of flight delay percentage according to time
a = sns.lineplot(data=proportions, palette="tab10", linewidth=2.5)
plt.xlabel("Scheduled Hour of Flight Departure")
plt.ylabel("Percentage")
plt.title("Percent of flights significantly delayed, by time of day")
plt.xticks(range(0,24,4), ['12am','4am','8am','12pm','4pm','8pm'])
plt.ylim(0, 40)
sns.move_legend(a, "upper left", bbox_to_anchor=(1, 1))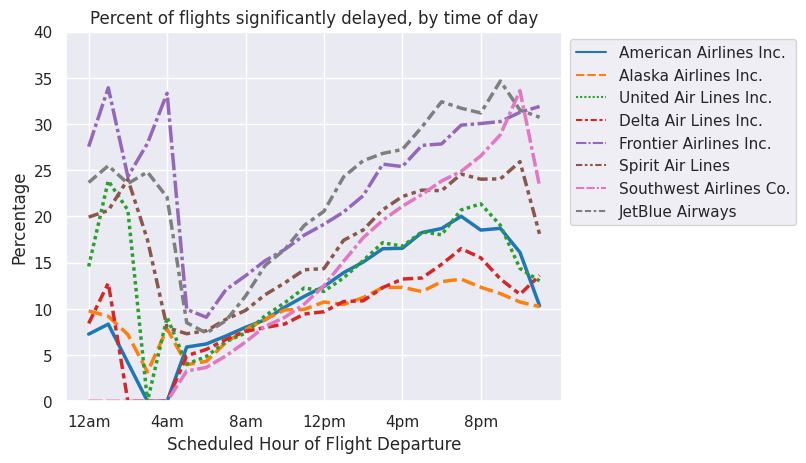
Regardless of airline, the chance of significant delay is lowest in the early hours of the morning, regardless of airline. From there, the probability of delay steadily increases and peaks in the evening. Then there is a dip around midnight, with delays skyrocketing in the wee hours of the morning. Many of these flights are budget airline red-eyes from Alaska and Puerto Rico that occur at the end of an airline’s work day, which can be later than 2am in those areas. Flying at the end of the work day increases the chance of delay since planes fly multiple flights in a day, and any delay in an earlier flight can mess up the traffic control schedule for all later flights. Additionally, if delayed for too long, crew duty hours can also exceed the limit. This happened in Southwest’s meltdow last year, where Southwest had insufficient replacement crews and misallocation of planes, leading to mass flight cancellations.
The budget airlines (Frontier, Spirit, Southwest, and JetBlue) all have higher rates of delay throughout the day according to this dataset, with the exception of Southwest, which has a delay rate comparable with the non-budget airlines in the morning. However, by 12pm, Southwest’s significant delay rate grows past that of the non-budget airlines and joins its budget peers by 4 or 5 pm.
By the numbers:
(delays.groupby('Airline').count()[['CRSDepTime']] / flights.groupby('Airline').count()[['CRSDepTime']] * 100).sort_values('CRSDepTime', ascending=False).rename({'CRSDepTime':'% Flights Significantly Delayed'}, axis=1)| % Flights Significantly Delayed | |
|---|---|
| Airline | |
| JetBlue Airways | 22.078514 |
| Frontier Airlines Inc. | 21.896298 |
| Allegiant Air | 18.991785 |
| Spirit Air Lines | 16.958591 |
| Southwest Airlines Co. | 15.292280 |
| American Airlines Inc. | 14.529106 |
| Mesa Airlines Inc. | 13.838768 |
| United Air Lines Inc. | 12.994220 |
| Hawaiian Airlines Inc. | 11.101448 |
| PSA Airlines Inc. | 11.007379 |
| Delta Air Lines Inc. | 10.671968 |
| SkyWest Airlines Inc. | 10.629637 |
| Alaska Airlines Inc. | 10.458504 |
| Republic Airline | 10.361243 |
| Endeavor Air Inc. | 9.843149 |
| Envoy Air | 9.762695 |
| Horizon Air | 8.873647 |
Since starting college, I’ve traveled quite regularly on planes between my hometown in Southern California and my university in the San Francisco Bay Area. I was drawn to this topic to get a better sense of which airline and airport combination offered me the fewest overall delays. As a college student with a constrained budget, I often take Southwest to and from school due to its cheap fares and customer service..
Southern California common wisdom dictates that one should fly out of Burbank (BUR) whenever possible to avoid the hassle of traveling to and out of Los Angeles (LAX).. Coming to the Bay Area for college, I expected Oakland (OAK) and San Francisco (SFO) to share a similar dynamic. add another sentence here for a better flowHowever, I was surprised to hear that some of my friends preferred SFO over OAK. In this section, we will determine whether SFO is better than OAK and BUR is better than LAX.
I follow a similar approach as before but select only flight records that contain our desired airports.
def compare_airports(airlines, airports, delays, flights):
""" Returns a DataFrame with delay rates by airport and airline. Indices follow the format 'airline airport.'
airlines' and airports must be lists. delays and flights are DataFrames as created above.
"""
proportions = pd.DataFrame()
for airline in airlines:
for origin in airports:
proportions[airline + " " + origin] = airline_delay_frequencies(airline,
delays[delays['Origin'] == origin], flights[flights['Origin'] == origin])
return proportions
# Construct a bar plot of flight delay percentage according to time
a = sns.lineplot(data=compare_airports(['Southwest Airlines Co.'], ['LAX', 'BUR', 'OAK', 'SFO'], delays_ma, flights_ma))
plt.xlabel("Scheduled Hour of Flight Departure")
plt.ylabel("Percentage")
plt.title("Percent of flights delayed by airport, airline")
plt.xticks(range(0,24,4), ['12am','4am','8am','12pm','4pm','8pm'])
sns.move_legend(a, "upper left", bbox_to_anchor=(1, 1))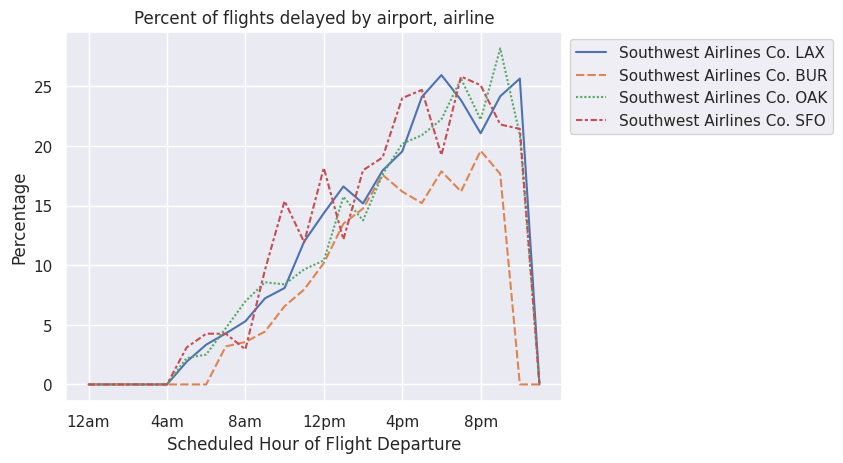
We see that BUR has fewer delays than LAX, OAK, and SFO. Burbank is better than LAX, but Oakland and SFO are about the same. Maybe my friends’ preference for SFO compared to OAK stems from something else, but clearly delays don’t play a major role in that decision.